
Pyramid Systems, Inc. (Pyramid) interns successfully developed an adaptable end-to-end data pipeline within the Google Cloud Platform (GCP), facilitating streamlined data processing for machine learning and artificial intelligence applications. The pipeline empowers Pyramid’s data scientists to efficiently ingest, prepare, analyze, and visualize data, laying the foundation for future innovation and insights.
Project Overview
Before initiating the pipeline development, a data science/ML problem was defined to set the project’s focus on exploring tools for each pipeline stage. The task selected involved identifying banks located in disaster hot zones using publicly available data from the Federal Deposit Insurance Corporation (FDIC) and the Federal Emergency Management Agency (FEMA.
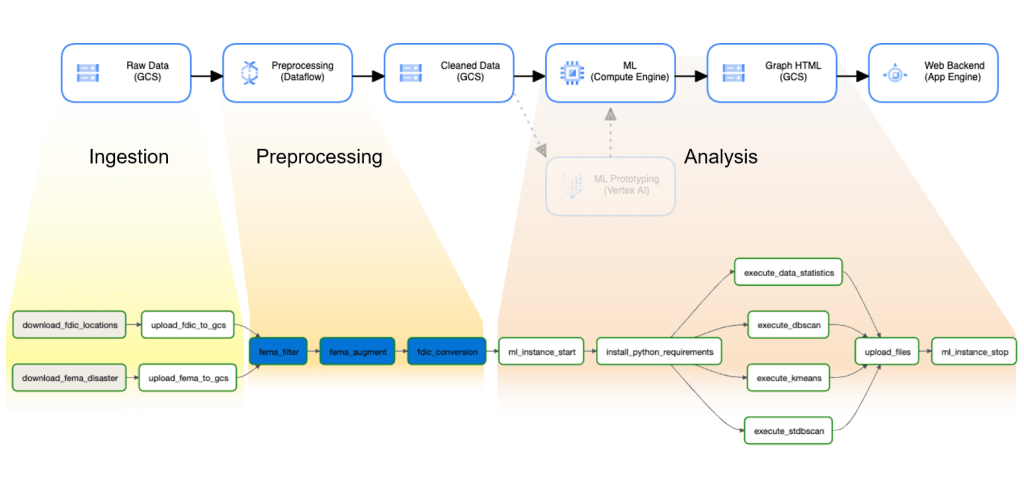
The pipeline was divided into four stages: Ingestion, Preparation, Analysis and Visualization. This created an end-to-end workflow from raw data to easy-to-read graphs presented in a website that Pyramid developed. Google Cloud Storage (GCS) buckets were used as interfaces between stages, storing the intermediate representation of the data at each stage. Choosing GCP as the host for its comprehensive suite of services and documentation, Pyramid was able to expand this solution from AWS to new platforms.
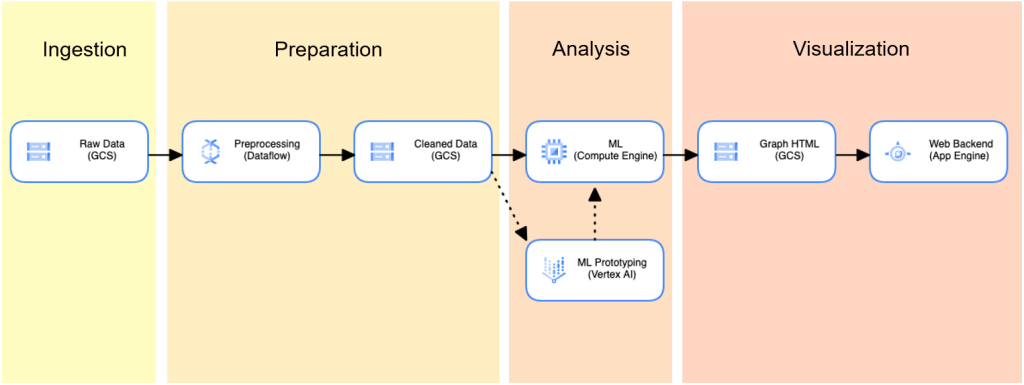
Ingestion
This stage involved the initial gathering and importing of raw data into the system. Ingestion was implemented using an Apache Airflow operator on a Google Cloud Composer. The operator downloaded data from the source (public data from FDIC and FEMA websites) into a GCS bucket. Parallelization for the purpose of making the ingestion process run faster was not an option for our pipeline because both the FDIC and FEMA datasets were downloaded as a single file. However, ingestion can benefit from parallelization in problems with larger datasets that are sourced from multiple files. An Airflow operator can be set up for each source file, and Cloud Composer will schedule them to run parallel when possible.
Preparation
This stage involved raw data undergoes cleaning, transformation, and structuring to make it suitable for analysis. Our three primary preprocessing subtasks were as follows: filter incomplete or extraneous FEMA disaster entries; convert the Federal Information Processing Standard (FIPS) codes used by FEMA; and convert the street address data used by FDIC. Preprocessing was completed using Google Dataflow, a cloud-based data processing service that optimizes performance by automatically identifying opportunities for parallelization and data shuffling.
Analysis
In the analysis phase, clustering algorithms were employed to identify patterns and groupings within the FEMA disaster data, which helps in pinpointing hot zones susceptible to various disaster types. For this particular project, three different clustering algorithms—kNN, DBSCAN, and Filtered DBSCAN—were utilized to cluster the FEMA data effectively. Once the hot zones were generated using these clustering algorithms, k-means clustering was applied to map bank locations to nearby clusters, aiding in understanding the geographical distribution of banks in relation to disaster-prone areas.
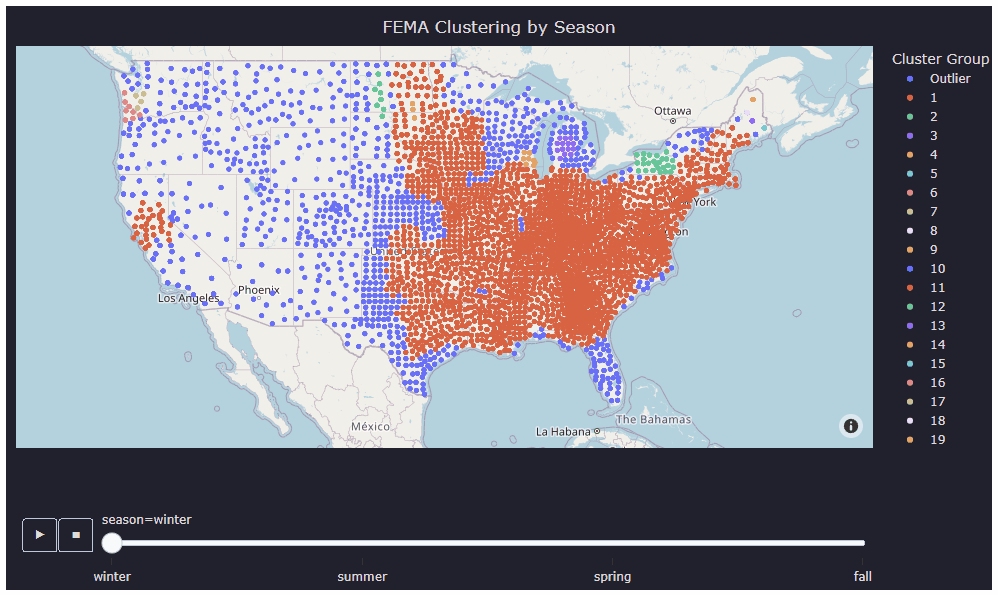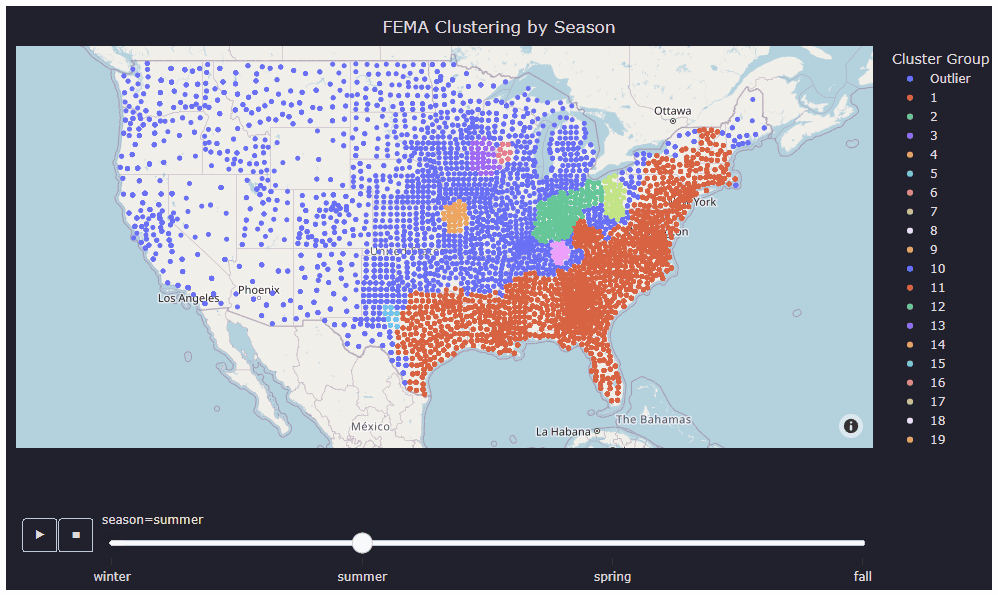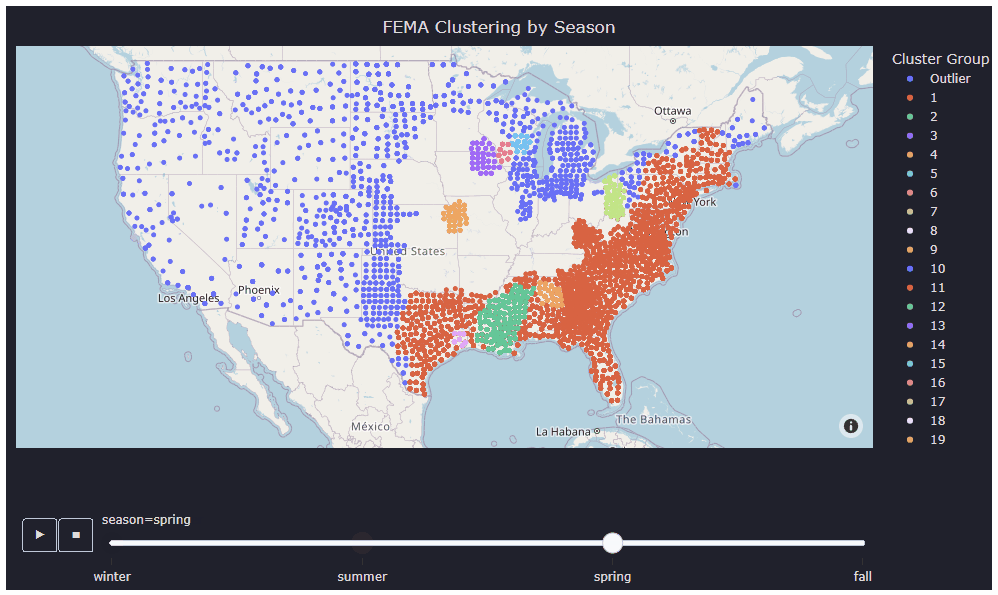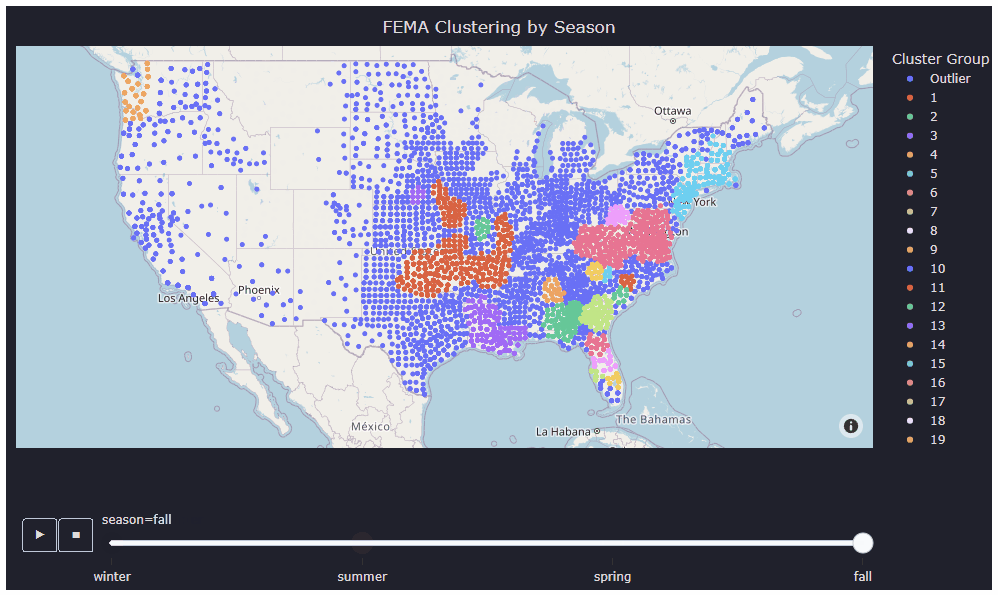
Visualization
To showcase the findings, a demo website was developed using the React library. The webserver was hosted on Google App Engine. The website seamlessly integrates HTML elements, simplifying the process of updating the graph by only requiring modifications to the HTML elements stored in the cloud.
Automation
Recognizing the periodic updates of FDIC and FEMA datasets, the team designed the pipeline to execute every six months, ensuring the display of up-to-date disaster hot zones. This automation was facilitated through Cloud Composer, enabling the definition and description of task dependencies with an Apache Airflow Directed Acyclic Graph (DAG). Airflow supports various operators for direct interaction with GCP, such as initiating Beam jobs or instances, with users required to define their specific DAG depending on the task.
Conclusion
Our team of interns assembled a pipeline on GCP that is designed to handle large volumes of data. This deliverable can be extended easily to accommodate new data sources and processing requirements. Pyramid’s AI/ML model offers invaluable relevance for many industries and communities by providing predictive analytics capabilities.